
Towards efficient generative AI and beyond-AI computing: New trends on ISSCC 2024 machine learning accelerators
Published:
Four trends toward efficient generative AI and beyond-AI computing
Trend 1: ML chips for generative AI
Related Work
- AMD MI300 series ()[]</br>
Technical composition: chiplet + AMD’s first-ever integration of data center class CPU, GPU + AMD Infinity Cache + 8-stack HBM3 memory system + advanced packaging technology
- MI300X: CPU hosted PCIe® device 针对传统的双路(2P)CPU服务器,托管8个GPU加速器,用于大型AI模型训练与推理
- 8 AMD CDNA architecture-based GPU chiplets + a unified AMD Infinity Cache(用于保持多个chiplet之间的硬件一致性) + AMD Infinity FabricTM network on chip (NoC) + HBM3 memory + external Infinity Fabric and PCIe® Gen 5 links
- MI300A: self-hosted accelerated processing unit (APU)
- 3 AMD “Zen 4” CPU chiplets with 6 AMD CDNA 3 GPU chiplets + AMD Infinity Fabric NoC + sharing a unified AMD Infinity Cache backed by HBM3 DRAM
- The most impressive part is that MI300 makes 13 pieces of silicon behave as one chip (3D integration, chiplet, packing, hybrid bonding .etc). 参见以下IEEE Spectrum
- About 3D V-Cache
- About hybrid bonding and this zhihu blog, this blog
- AMD-Chiplet zhihu blog Paper:Pioneering Chiplet Technology and Design for the AMD EPYC™ and Ryzen™ Processor Families : Industrial Product ISCA 2021
- 理解 The Product Portfolio Multiplier
- 摩尔定律失效导致的问题:半导体公司需要继续交付晶体管数量更多的产品,以市场友好的价格为客户提供更多的功能和计算能力,但摩尔定律的瓦解推迟了交付额外器件的新工艺节点的可用性,成本也在增加。
- Figure 5 单片SoC传统制造流程,需要通过 “known good die” (KGD) testing;使用chiplet使得被丢弃的硅数量更少,还可以测试单个chiplet的最大性能(clock),并将更快的chiplet组装成fast cores; ———— chiplet技术提高原始功能良率(raw functional yield rates)并增加高性能产品的供应
- 在引入新工艺技术节点的早期,良率往往低于成熟工艺。因此,试图在新新工艺节点早期构建大型SoC更具经济挑战性。然而,通过利用一组产量高得多的小芯片,可以比传统的单片设计更早地过渡到新的工艺节点。
- 通过组装chiplet得到超越光刻极限的单片芯片面积
- chiplet的代价:
- 更多的前期工作,将SoC划分为正确数量和正确类型的芯片(SoC分区要满足成本限制、性能要求、IP易用性和硅重用等要求)
- 还需要新的芯片间通信路径。与片上金属相比,这些互连涉及更长的路由,可能具有更高的阻抗、更低的可用带宽、更高的功耗和/或更高的延迟。互连开销还可能包括用于交叉电压和时序域、协议转换和/或串行-反序列化器(serializer-deserializers, SerDes)的电路,这些电路都代表了在单片设计中不存在的额外功率和硅面积开销
- 其他电路和功能也需要以每个芯片为基础进行复制。e.g.测试和调试接口(用于组装前测试单个芯片),时钟生成和分配,电源管理,片上温度传感器,I/O(例如USB, SATA)。因此,单个单片T型晶体管SoC的总硅面积面积(SoC(T))通常小于n个小芯片的总面积,其中每个小芯片具有面积(SoC(T/n)+K)的芯片面积,其中K代表上面讨论的额外开销(例如,芯片间接口,测试电路)。然而,与单片方法相比,为n个独立的小芯片使用更多的总硅面积仍可能导致更低的总成本
- 第一代AMD EPYC™处理器(霄龙服务器处理器):32 cores, 8 DDR4, 128 PCIe®gen3, 在14nm制程中需要777mm2的芯片面积(假设)
- 采用四个芯片组合的方式,每个芯片提供8个“Zen”CPU内核,2个DDR4内存通道,32个PCIe通道每个晶片的14nm制程的晶片面积为213 mm2,总的晶片面积为4 * 213mm= 852 mm2。与假设的单片32核芯片相比,~10%的芯片面积开销,但四晶片设计的最终成本仅为单片方法的约0.59x
- 优势
- 1、 即使面对一些制造缺陷,也可以利用每块晶圆中芯片总数的更高比例;
- 2、只需一次chiplet设计(即一个掩模组,一次流片),就可以提供多个不同的产品,而这些产品传统上需要多个独立的不同SOC
- 3、 Chiplet方法使得提供具有完整内存和I/O功能的产品更加实用 ———— 专用的16核单片SoC本身无法承受如此多内存通道和I/O通道所需的额外芯片面积的成本负担。然而,单个小芯片的较低成本加上在多个产品上摊销额外内存和I/O接口的能力,可以使这成为一种经济可行的方法,同时实现有价值的产品差异化,以满足客户需求。
- 劣势
- 1、chiplets need to communicate across the Infinity Fabric™ on-package (IFOP) interconnect, which are implemented as point-to-point links directly on the organic package substrate. —> additional interconnect latency
- 2、与PCIe gen3等封装外I/O的SerDes(每比特消耗约11pJ)相比,IFOP SerDes针对更短的封装基板布线长度进行了精心优化(每比特2pJ的能效),但与单片芯片(片上互连功率通常远低于每比特1pJ)相比还有功耗开销
- 3、一个chiplet上有8个CPU core,总共 8个DDR4内存通道中只有2个在同一个chiplet上。这意味着,在没有非一致性内存访问(non-uniform memory access, NUMA)数据管理和线程固定的情况下,某些内存请求必须由“远程”内存通道提供服务
- 4、对产生DRAM page misses的请求,同一chiplet上的本地内存通道的内存请求典型延时为90ns;访问不同chiplet、同一个socket的远程内存通道的延迟为141ns。这里额外的延时是 IFOP links和通过每个chiplet的本地data fabric(也称为片上网络或 NoC)的additional hops(布局设计中添加的额外连线或信号传输路径)的往返组合造成的。所以对于在8个内存通道之间均匀交错的内存访问模式,平均内存延迟为128ns。这些socket内NUMA影响是第二代 AMD EPYC™ 处理器解决的问题之一。
- 第二代AMD EPYC™处理器:双芯片方法。7nm 核心复合芯片(CCD)~74mm2 + 12nm I/O芯片(IOD)~416mm2(8个DDR4存储通道,128个PCIe gen4 I/O通道)
- “Zeppelin” chiplet 对工艺、面积与成本进行估算与权衡
- 1个IOD与8个CCD组装在一起。每个CCD提供8个“Zen 2”CPU内核,一个socket中可以集成64个内核。CCD提高了对7nm芯片的利用率,其上的8个CPU内核和L3 cache占芯片面积的86%。
- 在封装技术上,使用封装衬底路由(package substrate routing),而不是硅中介层实现的高密度互联。原因:
- chiplet的通信要求比较低,不至于用到硅中间层的这种更高级技术。由于有8个CCD和8个存储通道,平均每个chiplet的IFOP只需要处理大约1个DDR4通道的带宽。二封装基板路由层的点对点链路足以处理这种适度的带宽水平;而HBM可以提供数百GB/s的内存带宽,所以支持HBM的GPU需要更高带宽的方法,比如硅中间层。
- 基于中间层的互连的范围。虽然中间层可以为非常高的带宽提供很大的信号密度,但信号的长度是有限的,因此将连接限制为边对边链路。这将限制架构中只能放下4个CCD(如Figure 10)。
- 硅中间层制造的最新进展使十字拼接能够制造非常大的中间层,但成本过高,同时会导致较低的成品率和降低的可配置性。
- chiplet-封装协同设计的挑战
- 封装路由层被大量使用(IFOP,I/O,DDR4,电源和接地)。
- 这种具有挑战性的封装级连接需要设计和封装团队的协同设计,CCD、IOD和封装路由的总体布局和平面图必须一开始就进行协调。
- “Zeppelin” chiplet的VDDM供电(VDDM是支持L3缓存SRAM阵列的稳压供电轨)。VDDM由低压差( low-drop out,LDO)线性稳压器提供,该稳压器将功率驱动到封装基板中的厚铜层,以帮助将VDDM分布在L3缓存的整个区域。然后可以将功率发回给L3高速缓存供电。低阻封装层对于功率分配非常有效。
- 另一个挑战:在不同工艺节点中制造的chiplet通常使用不同的凸块间距将chiplet连接到封装基板,如12nm IOD凸块间距为150μm,而7nm CCD凸块为130μm。—>不同类型的小芯片在组装后将处于不同的高度,这对为冷却解决方案提供水平和均匀的接口带来问题。
- 解决方法:为IOD设计了一个基于铜柱的凸块,与7nm CCD兼容,以确保均匀组装后小芯片的高度。向铜柱封装接口的过渡还提供了更密集的凸块间距,并实现了更高的最大电流(电迁移)限制。
- 提高内存性能
- 第一代AMD EPYC处理器的内存和IO分布在四个小芯片上,提供了一种只需要单个小芯片设计的架构,但也引入了封装内NUMA(非统一内存访问)效应。此外,IFOP必须支持从芯片到远程内存通道的请求,从远程内核到本地内存通道的请求,以及两个方向的I/O。
- 第二代AMD EPYC™处理器小芯片的整体布局类似于星形拓扑,可提供更均匀的内存访问延迟。来自CCD的每个内存请求都直接跳到IOD,然后高性能Data Fabric从那里将请求路由到八个目标内存通道之一。请注意,某些存储通道仍然离每个CCD更近或更远,因此仍然存在一些NUMA效应,但与上一代方法相比,它们大大降低了。
- 总体成本和性能
- 显示了从 64 个内核到 16 个内核的五种不同可能配置的相对成本(7nm + 12nm 对比假设只用7nm)。
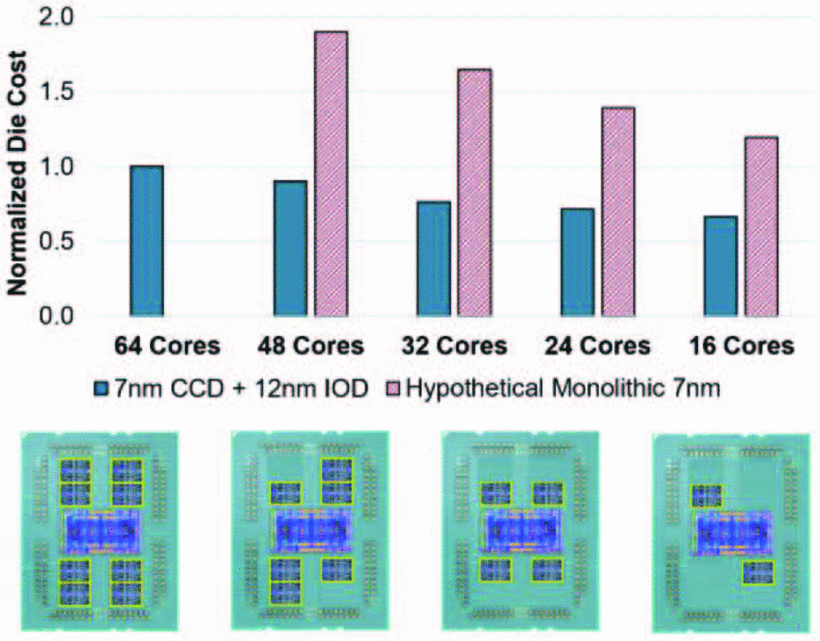
- 上图说明了几个重要的趋势,这些趋势真正证明了小芯片方法的力量和价值。首先,在所有配置中,最终的硅成本明显低于任何单片等效产品。其次,随着核心数量的变化,成本以平缓的斜率线性扩展。上图底部还说明了如何通过简单地从封装中减少 CCD 的填充来实现不同的内核数量。这直观地展示了如何仅通过两个流片(其中只有一个在领先的 7nm 节点中),能够灵活地启用整个服务器产品堆栈,包括 64 核选项,否则制造在技术和经济上都是不切实际的。
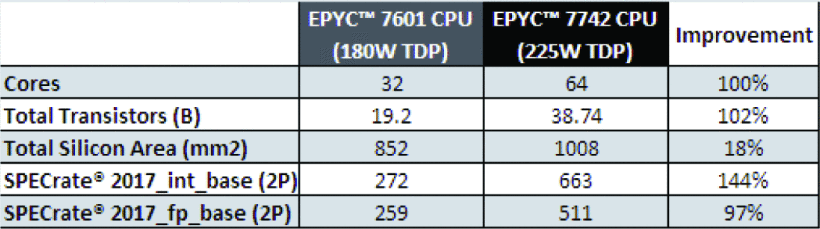
- 上图显示了第一代和第二代 AMD EPYC处理器的对比。小芯片方法使每个socket的总内核数翻了一番。晶体管的总数增加了一倍多,器件总数超过380亿个,而封装中的总硅面积仅增加了18%。该指标仅计算硅的总面积,对密度较大的7nm硅与14nm的处理没有任何区别,因此总硅的相对较小的增加突出了7nm工艺节点的密度优势。在上图最后显示了双插槽 (2P) 服务器平台 1 在 SPEC 速率®上测量的整体性能。性能提升是内核数量翻倍、时钟速度更高、更新的“Zen 2”微架构的更高 IPC 以及第二代产品更高的支持功率限制 (TDP) 的组合。
- 显示了从 64 个内核到 16 个内核的五种不同可能配置的相对成本(7nm + 12nm 对比假设只用7nm)。
- AMD Ryzen™ Processors(锐龙处理器)
- 第一代:单个“Zeppelin” chiplet放入client AM4 封装中,8 cores、2 DDR4、24 I/O lane的台式机处理器。
- 第三代:基于第二代AMD EPYC™ 处理器的芯片。2 CCDs(16 cores) and a “client IOD” (cIOD),如下图所示。其中CCD与之前的完全相同;cIOD是一个新芯片,在很大程度上利用了服务器IOD设计。
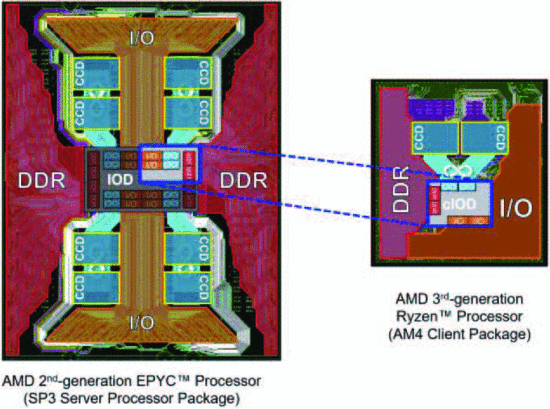
- 上图所示的cIOD面积125平方毫米、有20.9亿晶体管,2 DDR,32 PCIe 2IFOP to CCD,面积仅为服务器 IOD 的四分之一。
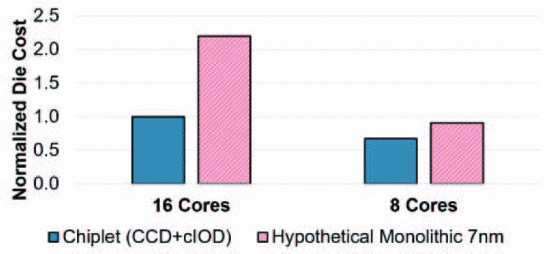
- 成本和性能:下图显示了16核(两个 CCD)和8核(一个 CCD)小芯片实现与假设的单片7nm设计相比的相对芯片成本。
</br>
- THU first heterogenous CIM-based accelerator for image-generative diffusion models